AI solving a real problem in my life — a family chat translator
My Polish parents and Egyptian in-laws share a WhatsApp group. I got tired of being the human relay, so I built a bot to translate for them.
Everyone’s talking about AI productivity gains. “10x developer.” “ChatGPT changed my life.” But when I asked engineer friends to show me their productivity data, guess how many had any? Zero. We’re all (well … at least I am :) ) paying $100-200/month for AI tools based on vibes. I decided to fix that for myself. I want to know whether my multi-agent system is actually worth the money, or if I’ve just built an expensive hobby.
Once you enter the vibe coding world and start reading what people actually think, you notice something: not everyone is thrilled. The productivity gains feel subjective. We might be paying for compute that doesn’t translate into real value.
This post is my way of dealing with that uncertainty. I’m trying to define a set of KPIs that, over time, will tell me if I’m actually getting faster, or just fooling myself.

I’m not trying to answer whether AI in general brings productivity gains. There’s a solid Stanford study I’ll link in a separate post that covers enterprise environments across projects and languages. My situation is different. I’m an engineering manager with a day job, hobbies, and a full life outside work. Before Claude Code and vibe coding, building side projects wasn’t even on my radar because the time and focus required to ship an app just wasn’t there. Now I can actually do it. I’ve already solved a couple of real problems around me this way.
So the question isn’t whether AI made me more productive. It did. The question is whether my latest round of optimization actually improved anything. This week I overhauled my whole workflow: added more agents, changed how the architect reviews the developer’s output, how the BA generates test cases, how all of it talks to each other. I feel like I’m faster.
But every vibe coder online says the same thing. Their setup is the best, they use MCP servers, productivity is through the roof. How would any of us know? We tend to deceive ourselves. Maybe I just think I’m coding faster with fewer mistakes, while in reality I’m burning more tokens per line and the defect rate hasn’t budged.
So I’m trying to answer a few specific questions: What’s my productivity baseline? Did my latest agentic changes actually move it? What metrics exist for measuring this? And can I apply them to my own projects?
It’s not just the $100 I pay monthly for Claude Code. It’s whether the work coming out of it is worth what goes in. If I’m burning through credits every Friday and hitting limits, I want to know if I’m squeezing real value out of those tokens or wasting them.
I think this can be optimized. Everyone gets the same credit pool, but some people clearly use it better than others. I want to figure out where I fall on that spectrum and how to move up.
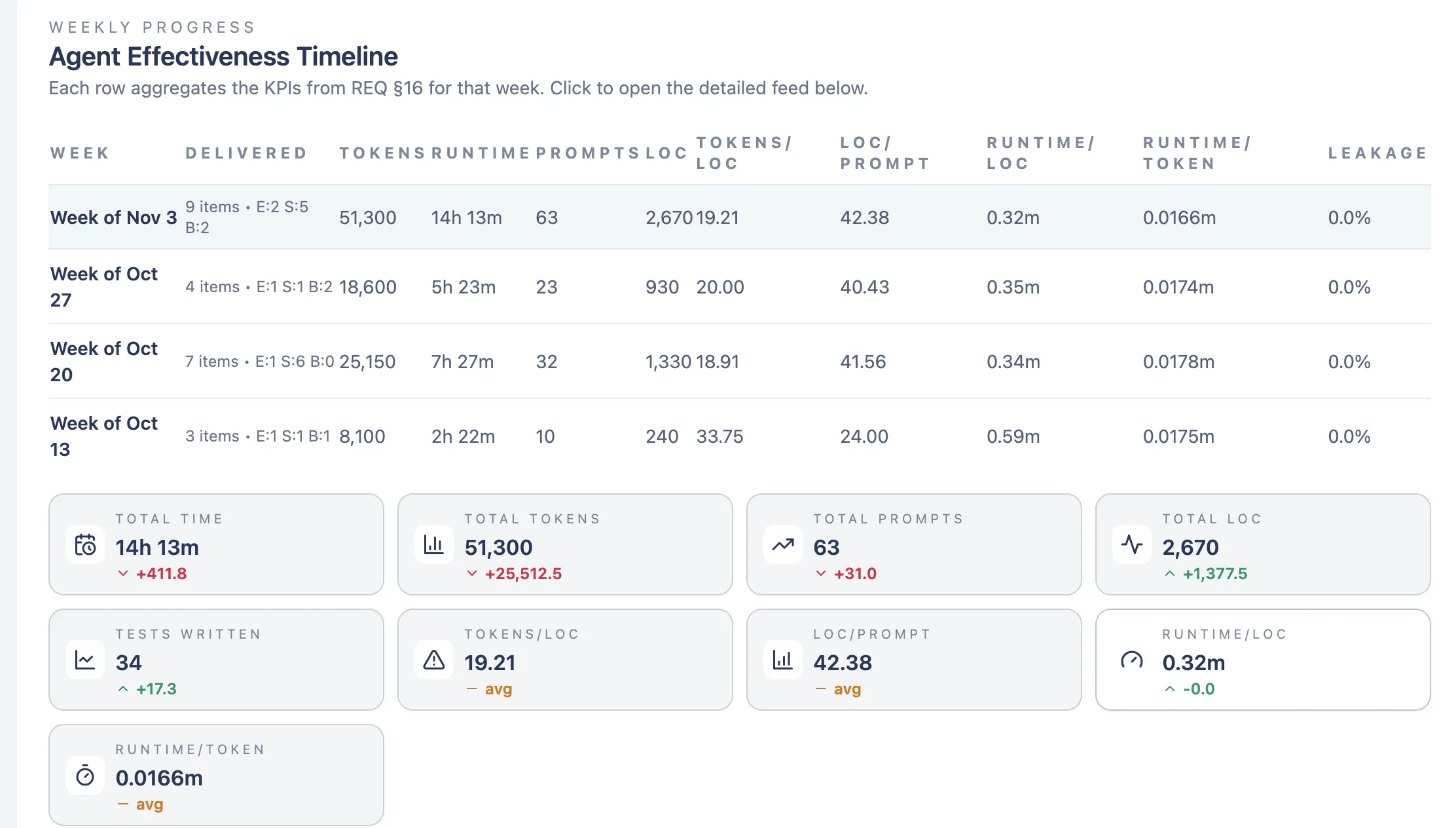
Honest truth: I don’t have a baseline yet. I’m just starting to collect data. Beginning this week, I’m changing how I manage tasks and will track the epics, stories, and bugs I deliver each week. For every effort, I’ll assign three values: business complexity, architecture complexity, and lines of code generated. Those are my comparison vectors.
Each item also gets a set of KPIs: agent runtime, tokens used, lines of code generated, and code quality indicators like complexity and churn (basically everything SonarQube gives you).
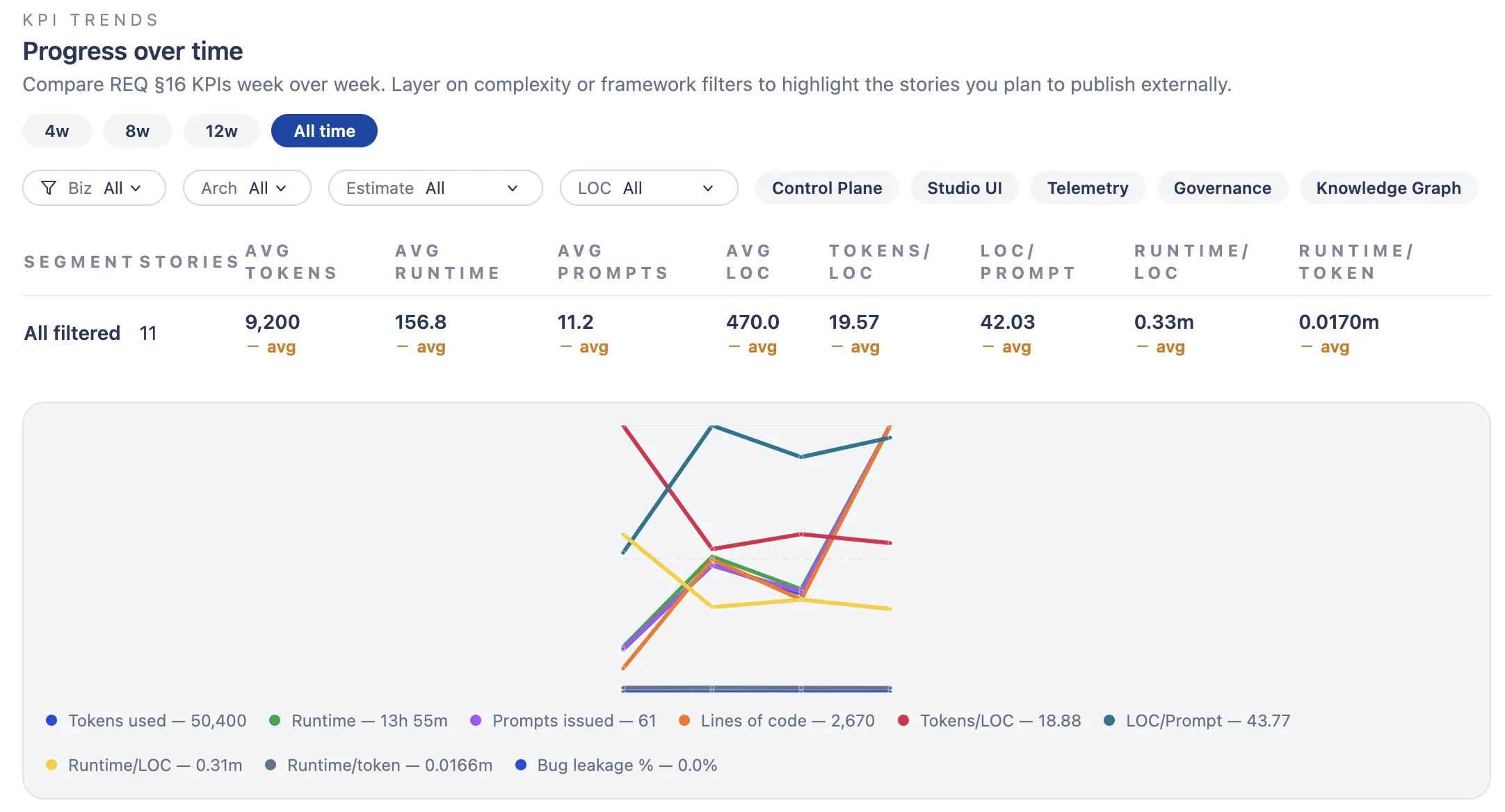
Every agentic setup gets versioned. If I change something, I know which configuration produced which results. Then I’ll watch ratios like:
The metric I care about most is output that actually ships. Code generated means nothing if it gets thrown away. Every week I want to finish with something delivered, measure its quality, and check defect leakage. I’ll compare week to week using the complexity KPIs I mentioned, and I’ll also track business outcomes: traffic, bug reports, leads, whatever applies.
I’m building a custom MCP server connected to my agentic framework. Every agent’s work gets reported there, with KPIs recorded per project and initiative. In 30 days I should have enough data to share actual results and see whether any of this optimization work is paying off.
That MCP server grew into its own project. AI Studio is an open-source MCP server that handles the full loop: story and epic management, agent definitions for each workflow phase, orchestration of multi-agent runs, and automatic telemetry for every agent execution. Tokens, cost, runtime, files changed, lines of code — all recorded without any manual setup.
The idea is that you break a feature into phases (PM analysis, codebase exploration, architecture, implementation) and assign a specialized agent to each one. You orchestrate the whole thing with MCP commands, and the system tracks what each agent produced and how much it cost. If you want to measure your own agentic setup the way I’m describing in this post, AI Studio gives you the infrastructure to do it.
It’s self-hosted, runs in Docker, and works with Claude Code or any MCP-compatible client. Check it out on GitHub if you want to try it yourself.
I’m also logging this visually so I can compare agents, configurations, and frameworks at a glance. These are the dashboards I check every Friday before deciding what to change next week:
Note: These visuals still show mocked data so I can validate the dashboards. The real numbers are now being collected and will replace the placeholders soon.
Continue reading
My Polish parents and Egyptian in-laws share a WhatsApp group. I got tired of being the human relay, so I built a bot to translate for them.
Twenty years across QA, product, and engineering leadership took me from Warsaw to Cairo. Here's why I started writing about it.
I shipped real-time video translation and a WhatsApp bot to solve actual family problems without a development team. Here's the step-by-step breakdown.